Summary
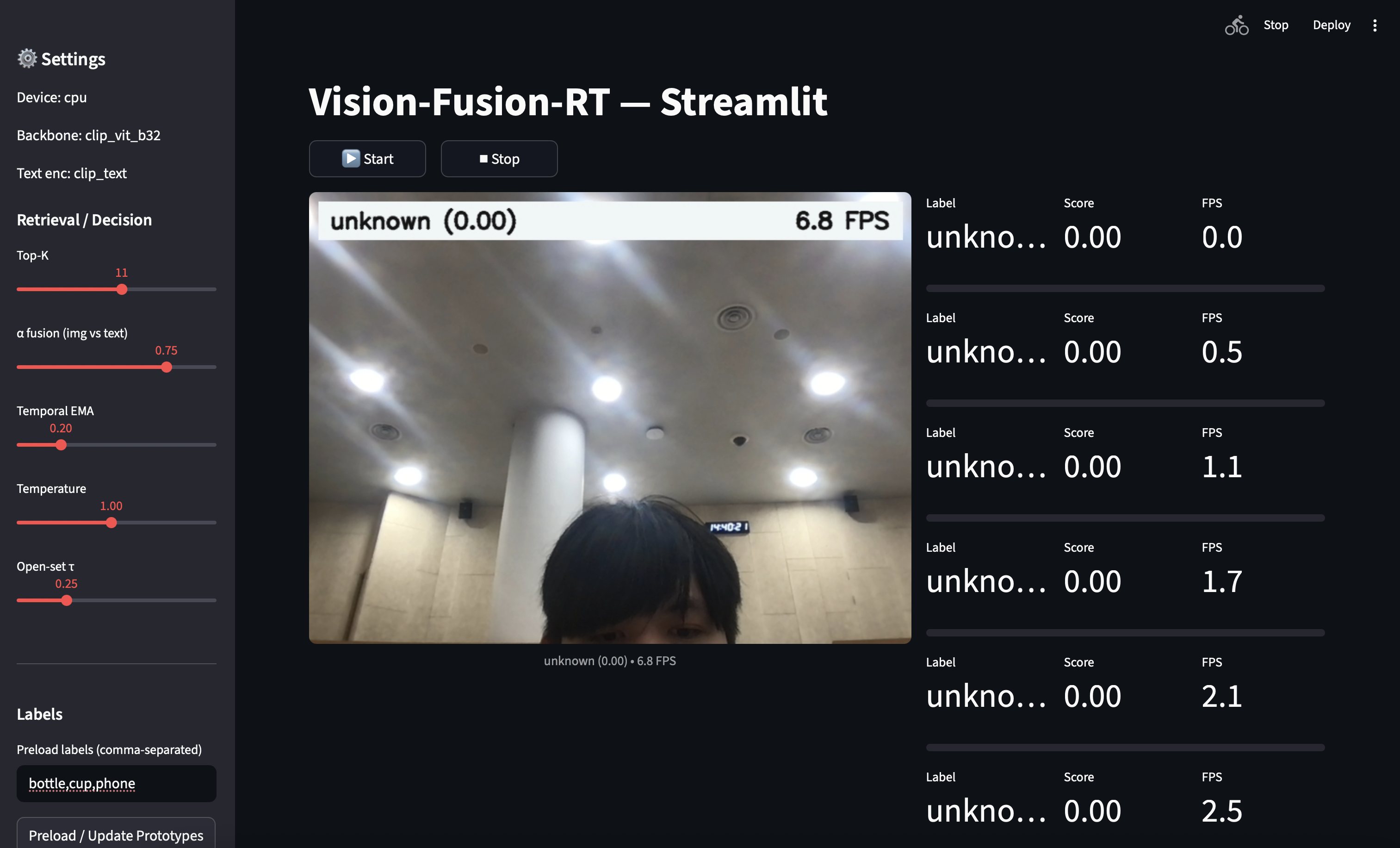
Vision Fusion Real Time (VFRT) is a real-time retrieval multimodial AI based demo that allows a visual input such as a webcam into a CLIP-powered object recognizer with a small, yet sufficient self-growing memory and adjustable text-prototype fusion. This real-time system introduces the concept of data retrieval without strictly relying on a pre-trained or fine-tuned model. This project is inspired with the recurring innovations of facial recognition systems, which is simultaneously linked to the project that I am currently working on. Furthermore, this demo ensures reproducibility as well as both a research and practical based modularity with the following specifications:
- Retrieve: Encode frames → search FAISS memory → aggregate neighbor votes.
- Fuse: Interpolate image scores with CLIP-Text prototypes (e.g., prompts like “a photo of a
{label}”). - Register on the fly: Press
[r]to capture a few recent frames and add a new class. - Open-set handling: Temperature and threshold for the unknown.
- Low-latency loop: Threaded webcam which captures with a bounded queue and borders (e.g., “
latest-frame” semantics). - Streamlit UI: Start/Stop, sliders for fusion/EMA/temperature, live overlay preview.
Research Purpose
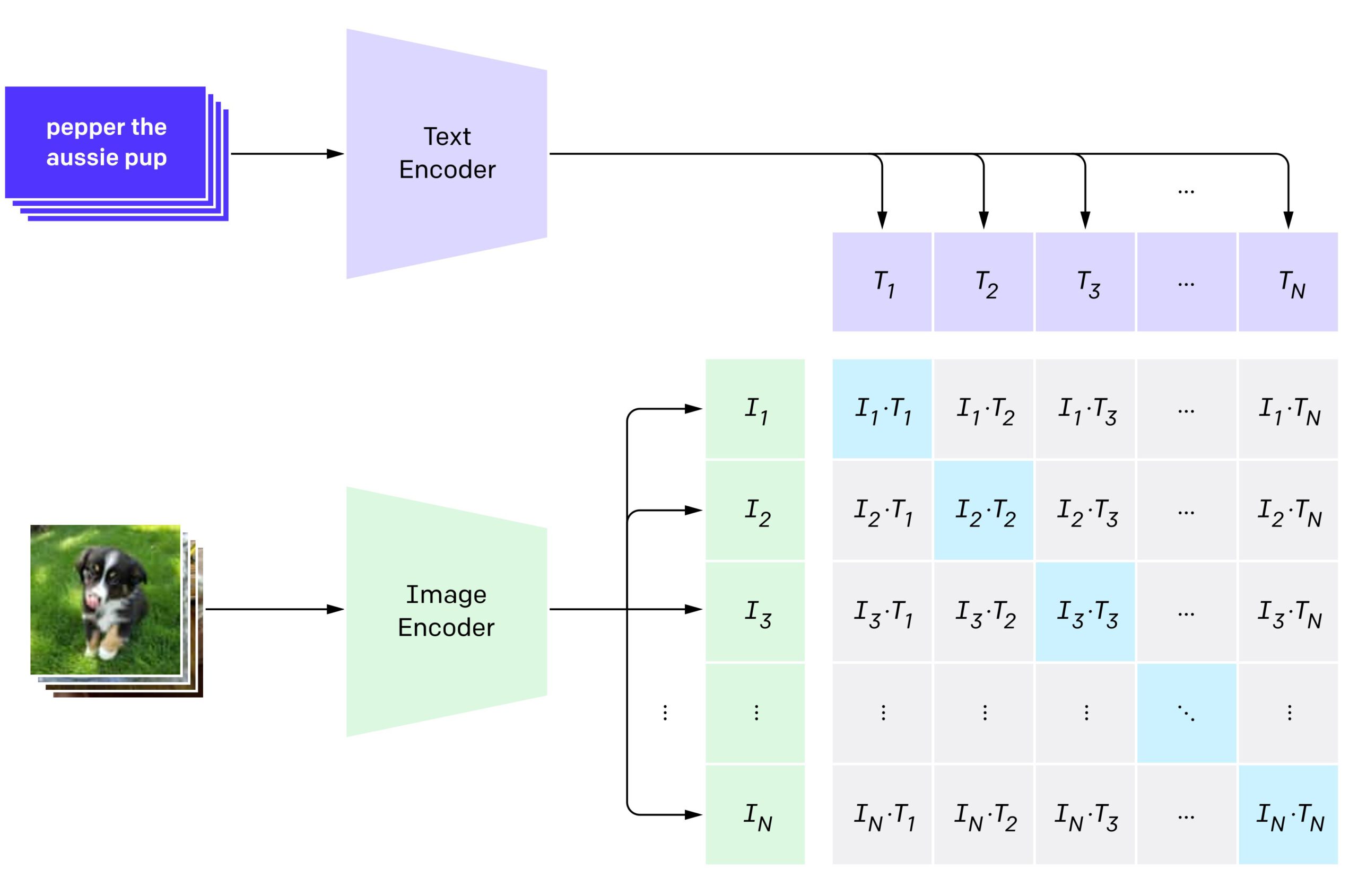
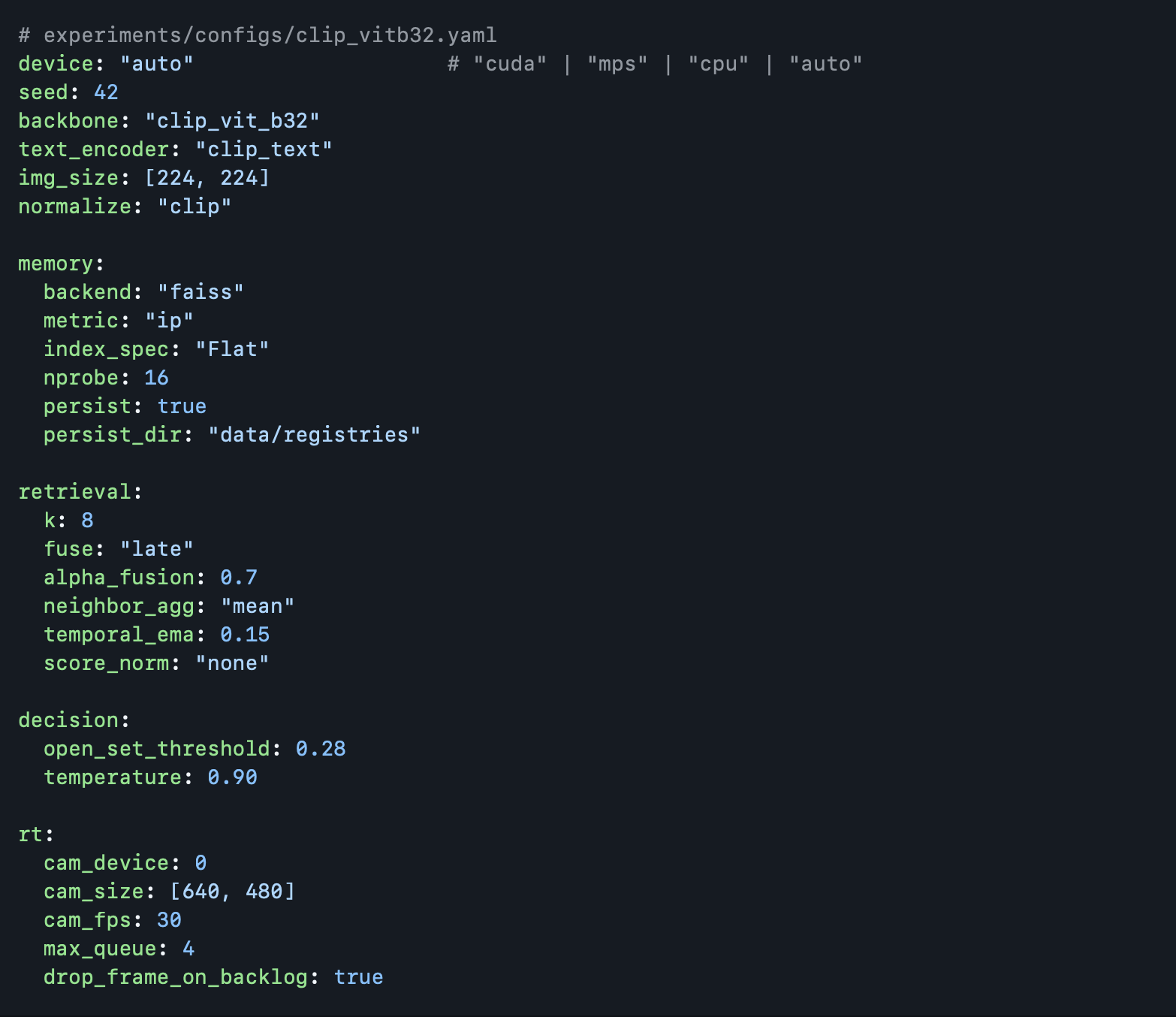
Modern multimodal models such as CLIP establish a joint latent embedding space where images and text can be directly compared using vector similarity. However, these models are often static, offline, and not incrementally adaptive. Real-world robotics, sensing, and real-time perception systems do not operate in offline curated datasets, rather they are required to adapt online as new objects appear, disappear, change lighting, orientation, texture, deformation, etc. The system uses CLIP image/text alignment and not a classifier. Rather, the system run as a semantic coordinate system. Furthermore, the system includes the following implementations:
- a dynamic incremental memory store (FAISS vector store).
- an online few-shot registration mechanism.
- a retrieval and fusion scoring based pipeline (kNN, text priors and EMA smoothing).
- a real-time control loop with camera → embedding → retrieve → decide → UI.
Future Roadmaps
- IVF/PQ FAISS indices and on-disk persistence.
- On-screen label editor and per-label undo.
- Batch evaluation scripts and CSV metrics.
- Alternative backbones (e.g., SigLIP, EVA-CLIP).
- WebRTC camera for remote browser demo.
- Domain: Computer Vision, Deep Learning, Human-Computer Interactions, Real-Time System
- Core: RAG, FAISS, CLIP, OpenCV
- Architecure: RAG, FAISS
- Focus: Clip Embeddings, Object Based Detection, Multimodal AI System